変な時間に起きてしまったので寝起きポエムでも書きます。
先日も講演依頼があったので恥ずかしいが簡単な自己紹介から入りました。
コンピュータ将棋参加は2017年の第5回電王トーナメントからで,電王トーナメントを見たのはその前年か第3回かくらいだったと思います。そもそも機械学習というものを触ったのが2017年でした。
偶然にも初参加で準優勝して以来世界選手権参戦し4年間1位か2位を維持しています。相当の強運かと感じます。
誤解があってはいけないのですが,まず例年皆相当強くなってます。
私は研究職と言う立場上技術的なものは独占より広く普及する方が良いと思っているので説明データが整い次第公表するようにしてます。参考にして頂いていることが多いので一年後には類似技術が普及する様子は分かります。
新技術を導入したものに対して単純な古典的レーティングを出すのは誤解が多くあまり適したものと思っていないので伏せておきますが,一年ごとに強化されており二年差あると別世界と言えるレベルで対戦成績が出ます。戦型もがらっと変わっている雰囲気です。
つまり一度上位を得たといってそれを維持するのは相当向上しているってことです。
上位陣の入れ替えを見れば分かるかもしれません。
それに加え強い方が勝つってのも漠然とした話でfloodgate的にも下剋上はイメージしているより多く発生しているのは分かると思います。
経験的にKristallweizenの評価関数公開直後などは非常に対戦成績が安定していたのですが,これは同じ評価関数で性能の違うPCで多数投入されていたんじゃないかと推察しています。これは完全に強弱で勝ち負けがきれいに割れます。
現状選手権前ってこともあって多種多様のエンジンが投入されています。特に私は多目に放り込んでいます。
正直運がいいだけだと第5回電王トーナメントでは思っていましたが,ある程度データを取ると統計的に優位が示されるという感じになっています。ただ,強い弱いが一列に並ぶイメージは未だもっていません。単純に戦型って話でもありません。
ざっくり将棋はそんなに浅くないって感じでしょうか。
事実私が事前調査した頃と比較して,平均手数でも相当変化が出ているとCSA瀧澤会長も近年強く強調されています。今は200手以上の棋譜が珍しくなくなりました。
もしかすると近いうちに囲碁の棋譜より長くなるのかもしれませんし,既に序盤中盤終盤の分類基準が変わって来ている感じもしています。定量的な再定義ができればとか考えています。
ええ,割とカオスな思考状態ですしそういう乱戦だと認識しています。
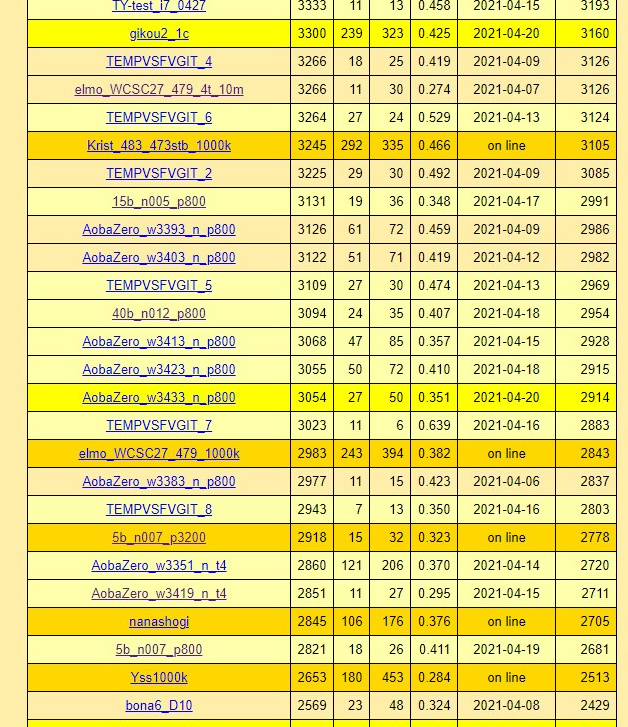
選手権前はfloodgateに投入して自分の位置を確認するのはそういう不安を払しょくする意味があるのでしょう。
実験系のエンジンは低めに,古い評価済みエンジンは高めのマシンで放り込んであります。興味ある人は御確認頂ければと思います。
Kristallweizen-TR2990WXが上位にいるままなんです。二年前の評価関数に二年前のPCです。ちょっと胃液上がってくる気分ですね。
今年の選手権は特に深層学習系がエントリー多いようですので対戦相性的な問題が多数発生しそうで乱戦必至といった感じでしょう。
たらたらと書いているうちに何か頭の整理になると思ったのですが無理ですね。
今年の選手権には松下さんに無理言って白ビールと二番絞りの両方を投入します。
floodgateより少し上の世界を二日間だけお見せできると思います。
(十分準備ができているとは言ってない)